Feedforward backpropagation is an error-driven learning technique popularized in 1986 by David Rumelhart (1942-2011), an American psychologist, Geoffrey Hinton (1947-), a British informatician, and Ronald Williams, an American professor of computer science.[1] It is a supervised learning technique, meaning that the desired outputs are known beforehand, and the task of the network is to learn to generate the desired outputs from the inputs.
Model
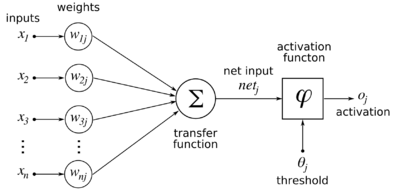
Model of a neuron.
j is the index of the neuron when there is more than one neuron. The activation function for feedforward backpropagation is sigmoidal.
Given a set of k-dimensional inputs with values between 0 and 1 represented as a column vector:
Error creating thumbnail: Unable to save thumbnail to destination
and a nonlinear neuron with (initially random, uniformly distributed between -1 and 1) synaptic weights from the inputs:
Error creating thumbnail: Unable to save thumbnail to destination
then the output of the neuron is defined as follows:
Error creating thumbnail: Unable to save thumbnail to destination
where
Error creating thumbnail: Unable to save thumbnail to destination
is a sigmoidal function. We will assume that the sigmoidal function is the simple logistic function:
Error creating thumbnail: Unable to save thumbnail to destination
This function has the useful property that
Error creating thumbnail: Unable to save thumbnail to destination
Feedforward backpropagation is typically applied to multiple layers of neurons, where the inputs are called the input layer, the layer of neurons taking the inputs is called the hidden layer, and the next layer of neurons taking their inputs from the outputs of the hidden layer is called the output layer. There is no direct connectivity between the output layer and the input layer.
If there are
Error creating thumbnail: Unable to save thumbnail to destination
inputs,
Error creating thumbnail: Unable to save thumbnail to destination
hidden neurons, and
Error creating thumbnail: Unable to save thumbnail to destination
output neurons, and the weights from inputs to hidden neurons are
Error creating thumbnail: Unable to save thumbnail to destination
(
i being the input index and
j being the hidden neuron index), and the weights from hidden neurons to output neurons are
Error creating thumbnail: Unable to save thumbnail to destination
(
i being the hidden neuron index and
j being the output neuron index), then the equations for the network are as follows:
Error creating thumbnail: Unable to save thumbnail to destination
If the desired outputs for a given input vector are
Error creating thumbnail: Unable to save thumbnail to destination
, then the update rules for the weights are as follows:
Error creating thumbnail: Unable to save thumbnail to destination
where η is some small learning rate,
Error creating thumbnail: Unable to save thumbnail to destination
is an error term for output neuron
j and
Error creating thumbnail: Unable to save thumbnail to destination
is a
backpropagated error term for hidden neuron
j.
Derivation
We first define an error term which is the cross-entropy of the output and target. We use cross-entropy because, in a sense, each output neuron represents a hypothesis about what the input represents, and the activation of the neuron represents a probability that the hypothesis is correct.
Error creating thumbnail: Unable to save thumbnail to destination
The lower the cross entropy, the more accurately the network represents what needs to be learned.
Next, we determine how the error changes based on changes to an individual weight from hidden neuron to output neuron:
Error creating thumbnail: Unable to save thumbnail to destination
We then want to change
Error creating thumbnail: Unable to save thumbnail to destination
slightly in the direction which reduces
E, that is,
Error creating thumbnail: Unable to save thumbnail to destination
. This is called
gradient descent.
Error creating thumbnail: Unable to save thumbnail to destination
We do the same thing to find the update rule for the weights between input and hidden neurons:
Error creating thumbnail: Unable to save thumbnail to destination
We then want to change
File:FfBp68.png slightly in the direction which reduces
E, that is,
Error creating thumbnail: Unable to save thumbnail to destination
:
Error creating thumbnail: Unable to save thumbnail to destination
Objections
While mathematically sound, the feedforward backpropagation algorithm has been called biologically implausible due to its requirements for neural connections to communicate backwards.[2]
References
- ↑ Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. (October 8, 1986). "Learning representations by back-propagating errors" Nature 323 (6088): 533–536
- ↑ Backpropagation: Theory, Architectures, and Applications. Chauvin, Yves; Rumelhart, David E. (1995). Lawrence Erlbaum Associates, Inc. ISBN 0805812598

{kind=link}
{kind=link}